3 min to read
Logistic Regression for Machine Learning Problem
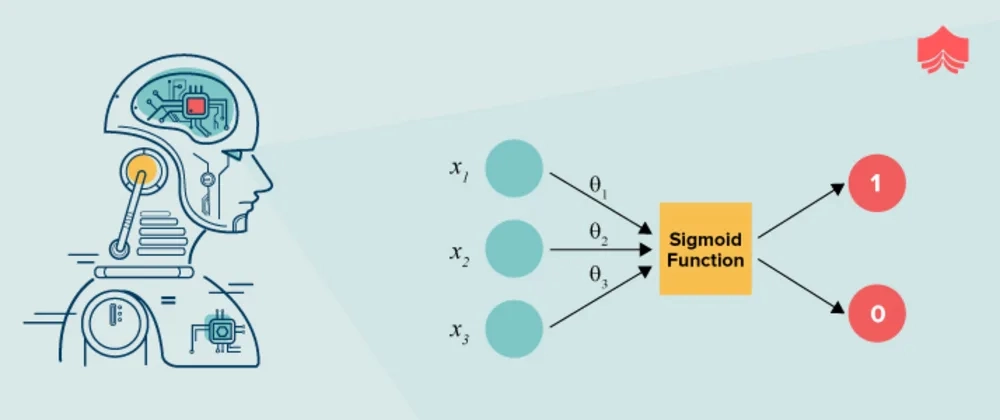
Logistic Regression is a kind of parametric classification model. and it’s a binary classification machine learning algorithm. In Binary classification, we predict the output in the form of 0 or 1. In this post, we will discuss logistic regression, how logistic regression works, assumptions for logistic regression, and how to implement logistic regression in python.
It can only be used to distinguish between 2 different categories like —
- Like if an E-mail is spam(1) or not(0).
- Whether the tumour is malignant (1) or not (0)
Introduction
It’s one of the most important algorithms in machine learning which widely used in classification problems. It’s a type of supervised machine learning which can predict the probability in the form of 0 or 1.
For example, if we want to predict whether user will click on the buy button or not. In this case, It will predict the probability of the user will click on the buy button or not on the basis of user’s behaviour, cart item, previous purchase, etc.

The theory behind Logistic Regression is very similar to the one from Linear Regression, so if you don’t know what Linear Regression is, take 5 minutes to read this Introduction. Check out the below link for linear regression quick introduction.
Types of Logistic Regression
- Binary Logistic Regression
- Multinomial Logistic Regression
- Ordinal Logistic Regression
How Logistic Regression Works
In logistic regression, with the help of the maximum likelihood method, algorithm will find predict the probability of the output. Logistic algorithm will find the best fit line which will predict the probability of the output.
Logistic Regression Equation
y = b0 + b1x1 + b2x2 + b3x3 + ... + bnxn
Maximum Likelihood Method
Maximum likelihood probability is the probability of the output. In logistic regression, we will find the maximum likelihood probability of the output.
Y = 1 / (1 + e^(-x))
The goal is simple, we want to find the best fit line to separate the data points. The best fit line will predict the probability of the output.
Assumptions for Logistic Regression
- For Logistic regression, there should be minimal or no multi collinearity among the independent variables.
- The Logistic regression assumes that the independent variables are linearly related to the log of odds.
- The Logistic regression usually requires a large sample size to predict properly.
- In Logistic regression dependent, the variable should be binary.
- The Logistic regression assumes the observations to be independent of each other.
Iris Flower Classification
It’s IRIS flower classification problem. In this problem, we will predict the type of flower on the basis of sepal length, sepal width, petal length, and petal width.
# Impoer Library for classification
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import Logi
from sklearn.metrics import accuracy_score
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import joblib
np.random.seed(10)
# split data for training and testing purpose
iris = load_iris()
X = iris.data
y = iris.target
train_X, test_X, train_y, test_y = train_test_split(X, y, train_size=0.8)
# Create pipeline
pipe = Pipeline([
('scaler', StandardScaler()),
('logistic',LogisticRegression(),)
])
# fit and predict
clf = pipe.fit(train_X, train_y)
pred_y = clf.predict(test_X)
score = accuracy_score(test_y, pred_y)
print(score)
Thanks for reading this post. I hope you like this post. If you have any questions, then feel free to comment below.



